Where can I get Microsoft DP-100 exam materials? Get the latest DP-100 exam dump, DP-100 pdf, and online practice tests to improve skills and experience, complete with Microsoft DP-100 dumps:: https://www.leads4pass.com/dp-100.html (Highest price/performance ratio, 100% pass rate)
Microsoft DP-100 exam pdf free download
[PDF Q1-Q13] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1OhiZlzvRXnztzWR36yIIMDLv5NtI5SFF
Exam DP-100: Designing and Implementing a Data Science Solution on Azure: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-100
The Azure Data Scientist applies their knowledge of data science and machine learning to implement and run machine learning workloads on Azure; in particular, using Azure Machine Learning Service. This entails planning and creating a suitable working environment for data science workloads on Azure, running data experiments and training predictive models, managing and optimizing models, and deploying machine learning models into production.
Skills measured
- NOTE: The bullets that appear below each of the skills measured in the document below are intended to illustrate how we are assessing that skill. This list is not definitive or exhaustive.
- Set up an Azure Machine Learning workspace (30-35%)
- Run experiments and train models (25-30%)
- Optimize and manage models (20-25%)
- Deploy and consume models (20-25%)
Latest Update Microsoft DP-100 Online Exam Practice Questions
QUESTION 1
HOTSPOT
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter,
training error, and validation errors.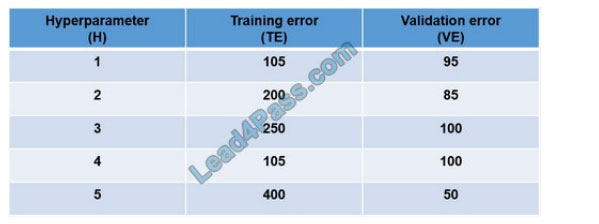
Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the graphic.
Hot Area:
Correct Answer:


Box 1: 4
Choose the one which has lower training and validation error and also the closest match.
Minimize variance (difference between validation error and train error).
Box 2: 5
Minimize variance (difference between validation error and train error).
Reference:
https://medium.com/comet-ml/organizing-machine-learning-projects-project-management-guidelines-2d2b85651bbd
QUESTION 2
You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module
may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

Box 1: Clean Missing Data
Box 2: SMOTE Use the SMOTE module in Azure Machine Learning Studio to increase the number of underepresented
cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than
simply duplicating existing cases.
Box 3: Convert to Indicator Values Use the Convert to Indicator Values module in Azure Machine Learning Studio. The
purpose of this module is to convert columns that contain categorical values into a series of binary indicator columns
that can more easily be used as features in a machine learning model.
Box 4: Remove Duplicate Rows
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/convert-to-indicator-values
QUESTION 3
HOTSPOT
You are performing sentiment analysis using a CSV file that includes 12.0O0 customer reviews written in a short
sentence format. You add the CSV file to Azure Machine Learning Studio and Configure it as the starting point dataset
of an
experiment. You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the
customer review column in the dataset.
You must create a new n-gram text dictionary from the customer review text and set the maximum n-gram size to
trigrams.
You need to configure the Extract N Gram features from Text module.
What should you select? To answer, select the appropriate options in the answer area;
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

QUESTION 4
You are moving a large dataset from Azure Machine Learning Studio to a Weka environment.
You need to format the data for the Weka environment. Which module should you use?
A. Convert to CSV
B. Convert to Dataset
C. Convert to ARFF
D. Convert to SVMLight
Correct Answer: C
Use the Convert to ARFF module in Azure Machine Learning Studio, to convert datasets and results in Azure Machine
Learning to the attribute-relation file format used by the Weka toolset. This format is known as ARFF.
The ARFF data specification for Weka supports multiple machine learning tasks, including data preprocessing,
classification, and feature selection. In this format, data is organized by entites and their attributes, and is contained in a
single text file.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/convert-to-arff
QUESTION 5
You plan to create a speech recognition deep learning model.
The model must support the latest version of Python.
You need to recommend a deep learning framework for speech recognition to include in the Data Science Virtual
Machine (DSVM).
What should you recommend?
A. Rattle
B. TensorFlow
C. Weka
D. Deeplearning4j
Correct Answer: B
TensorFlow is an open source library for numerical computation and large-scale machine learning. It uses Python to
provide a convenient front-end API for building applications with the framework TensorFlow can train and run deep
neural networks for handwritten digit classification, image recognition, word embeddings, recurrent neural networks,
sequence-to-sequence models for machine translation, natural language processing, and PDE (partial differential
equation) based simulations.
Incorrect Answers:
A: Rattle is the R analytical tool that gets you started with data analytics and machine learning.
C: Weka is used for visual data mining and machine learning software in Java.
References: https://www.infoworld.com/article/3278008/what-is-tensorflow-the-machine-learning-library-explained.html
QUESTION 6
You plan to preprocess text from CSV files. You load the Azure Machine Learning Studio default stop words list. You
need to configure the Preprocess Text module to meet the following requirements:
1.
Ensure that multiple related words from a single canonical form.
2.
Remove pipe characters from text.
3.
Remove words to optimize information retrieval.
Which three options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
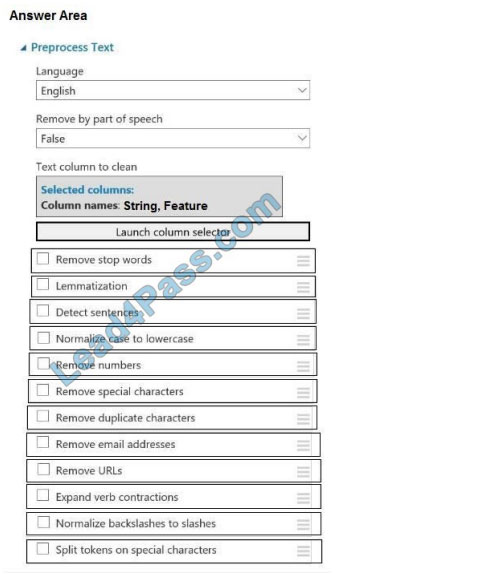
Correct Answer:
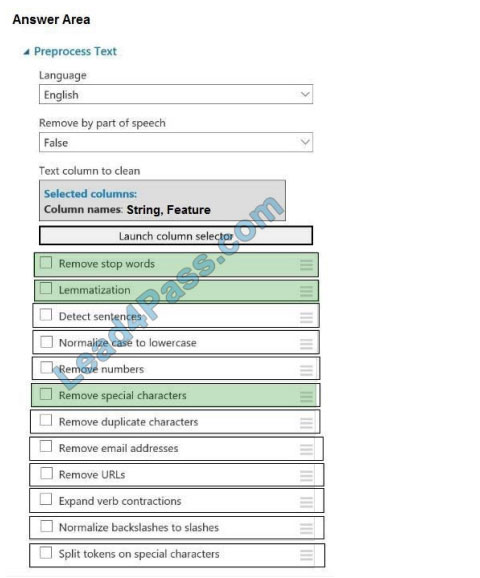
Box 1: Remove stop words
Remove words to optimize information retrieval.
Remove stop words: Select this option if you want to apply a predefined stopword list to the text column. Stop word
removal is performed before any other processes.
Box 2: Lemmatization
Ensure that multiple related words from a single canonical form.
Lemmatization converts multiple related words to a single canonical form
Box 3: Remove special characters
Remove special characters: Use this option to replace any non-alphanumeric special characters with the pipe |
character.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/preprocess-text
QUESTION 7
You are with a time series dataset in Azure Machine Learning Studio.
You need to split your dataset into training and testing subsets by using the Split Data module.
Which splitting mode should you use?
A. Recommender Split
B. Regular Expression Split
C. Relative Expression Split
D. Split Rows with the Randomized split parameter set to true
Correct Answer: D
Split Rows: Use this option if you just want to divide the data into two parts. You can specify the percentage of data to
put in each split, but by default, the data is divided 50-50. Incorrect Answers:
B: Regular Expression Split: Choose this option when you want to divide your dataset by testing a single column for a
value.
C: Relative Expression Split: Use this option whenever you want to apply a condition to a number column.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/split-data
QUESTION 8
DRAG DROP
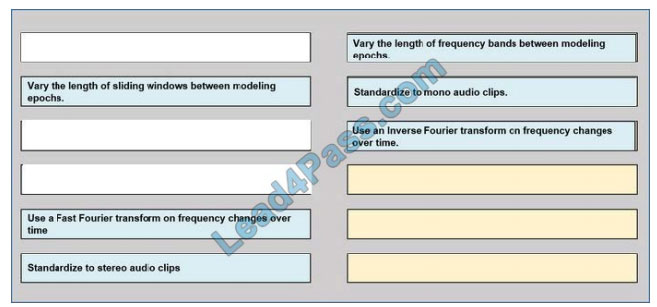
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
QUESTION 9
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
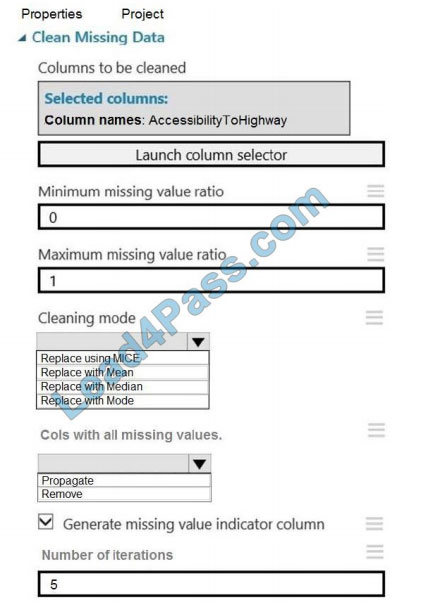
Correct Answer:
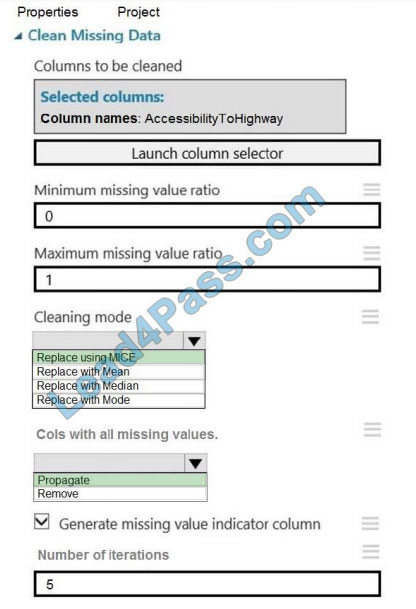
Box 1: Replace using MICE
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method
described in the statistical literature as "Multivariate Imputation using Chained Equations" or "Multiple Imputation by
Chained Equations". With a multiple imputation method, each variable with missing data is modeled conditionally using
the other variables in the data before filling in the missing values.
Scenario: The AccessibilityToHighway column in both datasets contains missing values. The missing data must be
replaced with new data so that it is modeled conditionally using the other variables in the data before filling in the
missing
values.
Box 2: Propagate
Cols with all missing values indicate if columns of all missing values should be preserved in the output.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 10
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are a data scientist using Azure Machine Learning Studio.
You need to normalize values to produce an output column into bins to predict a target column.
Solution: Apply a Quantiles binning mode with a PQuantile normalization.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Use the Entropy MDL binning mode which has a target column.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/group-data-into-bins
QUESTION 11
You use Azure Machine Learning Studio to build a machine learning experiment.
You need to divide data into two distinct datasets.
Which module should you use?
A. Assign Data to Clusters
B. Load Trained Model
C. Partition and Sample
D. Tune Model-Hyperparameters
Correct Answer: C
Partition and Sample with the Stratified split option outputs multiple datasets, partitioned using the rules you specified.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
QUESTION 12
HOTSPOT
You have a dataset that contains 2,000 rows. You are building a machine learning classification model by using Azure
Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
1.
Divide the data into subsets
2.
Assign the rows into folds using a round-robin method
3.
Allow rows in the dataset to be reused
How should you configure the module? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Use the Split data into partitions option when you want to divide the dataset into subsets of the data. This option is also
useful when you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Add the Partition and Sample module to your experiment in Studio (classic), and connect the dataset.
For Partition or sample mode, select Assign to Folds.
Use replacement in the partitioning: Select this option if you want the sampled row to be put back into the pool of rows
for potential reuse. As a result, the same row might be assigned to several folds.
If you do not use replacement (the default option), the sampled row is not put back into the pool of rows for potential
reuse. As a result, each row can be assigned to only one fold.
Randomized split: Select this option if you want rows to be randomly assigned to folds.
If you do not select this option, rows are assigned to folds using the round-robin method.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
Share leads4pass discount codes for free 2020

About the benefits and introductions of leads4pass
leads4pass offers the latest exam exercise questions for free! Microsoft exam questions are updated throughout the year.
leads4pass has many professional exam experts! Guaranteed valid passing of the exam! The highest pass rate, the highest cost-effective!
Help you pass the exam easily on your first attempt.
Summarize:
MeetExams shares the latest Microsoft DP-100 exam dumps, DP-100 pdf, DP-100 exam exercise questions for free. You can improve your skills and exam experience online to get complete exam questions and answers guaranteed to pass the exam we recommend leads4pass DP-100 exam dumps
Latest update leads4passDP-100 exam dumps: https://www.leads4pass.com/dp-100.html (125 Q&As)
[Q1-Q13 PDF] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/open?id=1OhiZlzvRXnztzWR36yIIMDLv5NtI5SFF